I’ve been diving into the world of MLOps lately, curious about how modern ML pipelines can be made more scalable and maintainable. Machine learning is so much more than just training a model, there’s data pre-processing, feature engineering, evaluation, deployment, and the ongoing need for everything to be reproducible.
As a DevOps engineer, I’ve spent years designing reliable workflows for CI/CD and infrastructure automation, but hadn’t explored how those same principles could apply to ML pipelines. That’s where Argo Workflows and Argo Events caught my attention. They’re lightweight, Kubernetes-native, and from what I’ve seen so far, they’re gaining real traction in the MLOps space.
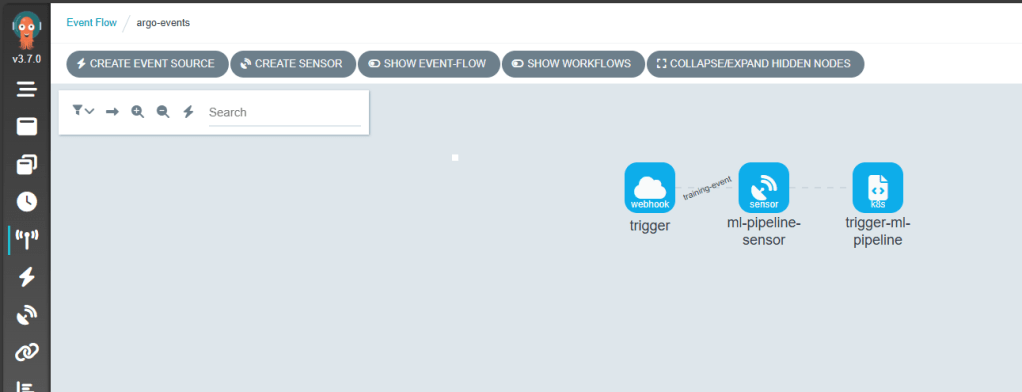
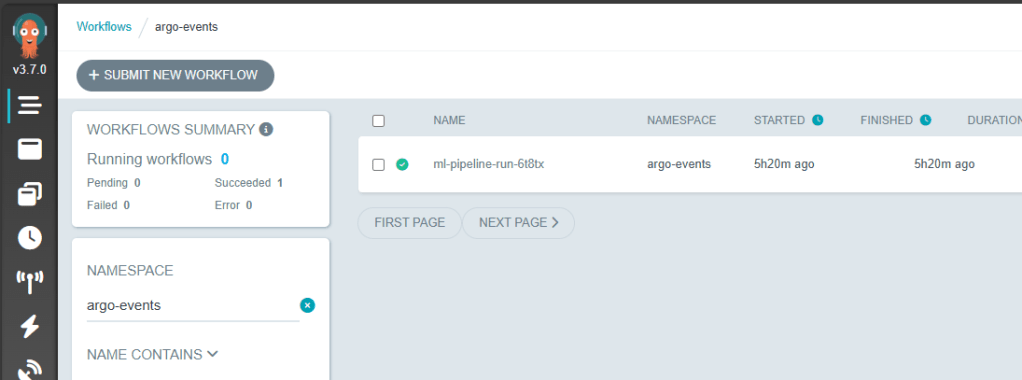
This post is my first hands-on look at these tools, setting up Argo Workflows and Argo Events on a local cluster with kind and exploring how they might enable event-driven, reproducible ML pipelines.
🧠Why Argo Workflows for MLOps?
Traditional ML pipelines are often stitched together using ad-hoc scripts, cron jobs, or heavy frameworks like Kubeflow. Argo Workflows offers a Kubernetes-native, lightweight alternative for orchestrating ML pipelines with:
Containerised tasks: Each step runs in its own container for reproducibility.
DAG-based workflows: Easily express complex pipelines with dependencies.
Event-driven triggers: With Argo Events, workflows can be launched automatically when new data arrives or other events occur.
Parallel execution: Fan-out tasks for hyperparameter tuning, multi-model training, or batch inference.
Retry strategies & exit handlers: Add robustness with built-in error handling and graceful exits.
Artifact management: Integrate with MinIO or volume mounts to persist model files, metrics, or datasets across steps.
Compared to tools like Kubeflow, Argo is simpler and less opinionated, making it easier to integrate with tools like MLflow, Seldon Core, etc. Its flexibility lets you tailor pipelines to your needs without locking into rigid frameworks.
🛠️Initial Setup
Here’s the setup I used for experimenting locally:
Argo Workflows and Argo Events have opened the door to scalable, event-driven ML pipelines, but there’s much more to explore:
📦 GitOps Delivery with ArgoCD
Pairing ArgoCD with Argo Workflows would enable declarative, version-controlled deployment of ML pipelines across environments. Imagine triggering new workflow templates from a Git commit and syncing changes automatically.
📡 Real-World Event Sources
How about connecting Argo Events to cloud-native services such as:
AWS SQS / SNS
Azure Service Bus
etc.
These integrations could allow upstream events to dynamically trigger ML pipelines.
🔧 Tool Integrations Ahead
What about adding further integration with popular tools:
MLflow – for experiment tracking and lifecycle management
KServe – to enable model serving within a Kubernetes-native stack
etc.
I hope this post sparked some ideas, go give Argo a spin and explore your own event-driven ML workflows!
As a .NET developer familiar with crafting CI/CD pipelines in YAML using platforms like Azure Pipelines or GitHub Actions, my recent discovery of Nuke.Build sparked considerable interest. This alternative offers the ability to build pipelines in the familiar C# language, complete with IntelliSense for auto-completion, and the flexibility to run and debug pipelines locally—a notable departure from the constraints of YAML pipelines, which often rely on remote build agents.
While exploring Nuke.Build’s developer-centric features, it became apparent that this tool not only enhances the developer experience but also provides an opportunity to seamlessly integrate security practices into the development workflow. As someone deeply invested in promoting developer-first application security, the prospect of incorporating security scans directly into the development lifecycle resonated strongly with me, aligning perfectly with my desire for rapid feedback on application security.
Given my role as a Snyk Ambassador, it was only natural to explore how I could leverage Snyk’s robust security scanning capabilities within the Nuke.Build pipeline to bolster the security posture of .NET projects.
In this blog post, I’ll demonstrate the creation of a pipeline using Nuke.Build and showcase the addition of Snyk scan capability, along with Software Bill of Materials (SBOM) generation. Through this proactive approach, we’ll highlight the ease of integrating a layer of security within the development lifecycle.
Getting Started
Following the Getting Started Guide on the Nuke.Build website, I swiftly integrated a build project into my solution. For the sake of simplicity, I opted to consolidate the .NET Restore, Build, and Test actions into a single target, along with adding a Clean target.
In Nuke.Build, a “target” refers to individual build steps that can be executed independently or in sequence. By combining multiple actions into a single target, I aimed to streamline the build process and eliminate unnecessary complexity.
Running nuke from my windows terminal built the solution and ran the tests.
Adding Security Scans
With the basic pipeline set up to build the code and run the tests, the next step is to integrate the Snyk scan into the pipeline. While Nuke supports a variety of CLI tools, unfortunately, Snyk is not among them.
To begin, you’ll need to create a free account on the Snyk platform if you haven’t already done so. Once registered, you can then install Snyk CLI using npm. If you have Node.js installed locally, you can install it by running:
npm install snyk@latest -g
Given that the Snyk CLI isn’t directly supported by Nuke, I turned to the Nuke documentation to explore possible solutions for running the CLI. Two options caught my attention: PowerShellTasks and DockerTasks.
To execute the necessary tasks for the Snyk scan, a few steps are required. These include authorizing a connection to Snyk, performing an open-source scan, potentially conducting a code scan, and generating a Software Bill of Materials (SBOM).
Let’s delve into each of these tasks using PowerShellTasks in Nuke. Firstly, let’s tackle authorization. The CLI command for authorization is:
snyk auth
Running this command typically opens a web browser to the Snyk platform, allowing you to authorize access. However, this method isn’t suitable for automated builds on a remote agent. Instead, we need to provide credentials. If you’re using a free account, your user will have an API Token available, which you can find on your account settings page under “API Token.” For enterprise accounts, you can create a service account specifically for this purpose.
To incorporate the Snyk Token into our application, let’s add a parameter to the code:
[Parameter("Snyk Token to interact with the API")] readonly string SnykToken;
Next, we’ll create a new target to execute the authorization command using PowerShellTasks and pass in the Snyk Token:
Including the --all-projects flag ensures that all projects are scanned, which is good practice for .NET projects. Additionally, I’ve added an exclusion for the build project to focus the scan on application issues. I typically rely on Snyk Monitor attached to my GitHub Repo to detect issues in the entire repository, leaving this scan to concentrate solely on the application being deployed.
Finally, we need to update the Execute method to include the Snyk Test:
public static int Main() => Execute<Build>(x => x.BuildTestCode, x => x.SnykTest);
Running nuke again from the Windows terminal now prompts for Snyk authentication
Once authenticated
In order to prevent this we need to pass the API token value to nuke. It’s a good idea to set an environment variable for your API token e.g. with PowerShell
$env:snykApiToken = "<your api token>"
# or using the Snyk CLI
$env:snykApiToken = snyk config get api
# Run nuke passing in the parameter
nuke --snykToken $snykApiToken
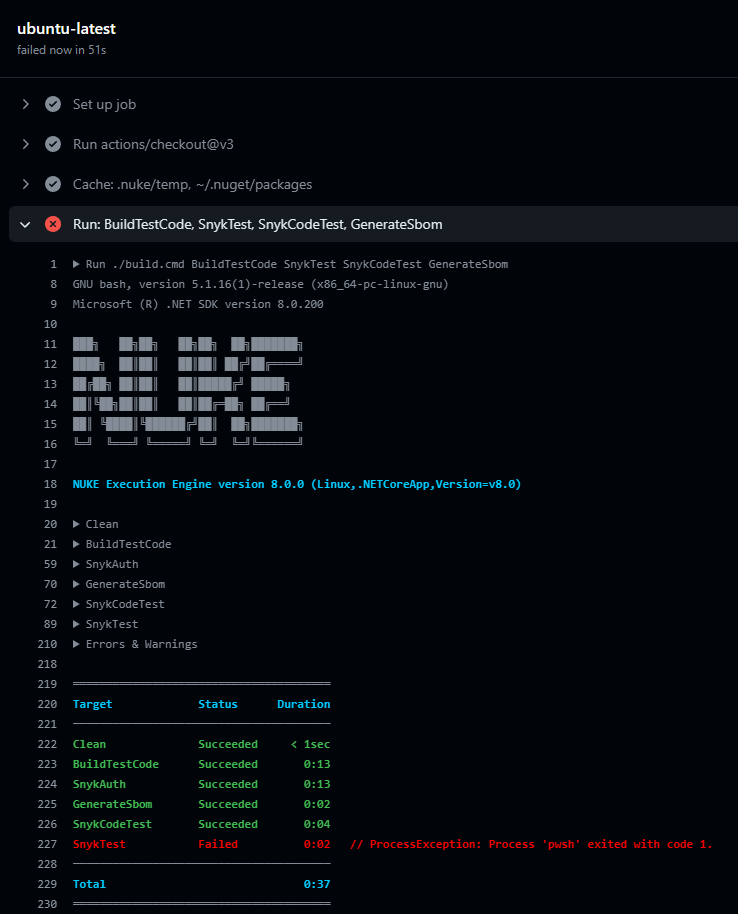
Upon executing the scan, it promptly identified several issues:
Subsequently, the Snyk Test failed, flagging vulnerabilities in the code and failing SnykTest:
To control whether the build fails based on the severity of vulnerabilities found, we can add another parameter:
[Parameter("Snyk Severity Threshold (critical, high, medium or low)")] readonly string SnykSeverityThreshold = "high";
Ensure that the value has been set before using it. Note that the threshold must be in lowercase.
Lastly, update the Execute method to include the generation of the SBOM:
public static int Main() => Execute<Build>(x => x.BuildTestCode, x => x.SnykTest, x => x.SnykCodeTest, x => x.GenerateSbom);
Now, when executing Nuke, the SBOM will be generated and stored in the specified directory, ready to be published as a build artifact.
Earlier, I mentioned that PowerShellTasks and DockerTasks were both viable options for integrating the Snyk CLI into the Nuke build. Here’s how you can achieve the same tasks using DockerTasks:
NOTE: Snyk Auth is not required as a separate task as that is done inside the snyk container
Automating Nuke.Build with GitHub Actions: Generating YAML
Nuke comes with another useful feature: the ability to see a plan, which shows which targets are being executed and when. Simply running nuke --plan provides an HTML output of the plan:
With everything configured for local execution, it’s time to think about running this in a pipeline. Nuke supports various CI platforms, but for this demonstration, I’ll be using GitHub Actions. Nuke provides attributes to automatically generate the file to run the code:
This YAML file is automatically generated by Nuke and is ready to be used in your GitHub Actions workflow. It sets up the necessary steps to run your build, including caching dependencies, executing targets, and publishing artifacts.
NOTE: When I first committed the nuke build files, GitHub Actions gave me a permission denied error when running build.cmd. Running these commands and committing them got over that problem
Nuke.Build is a great concept for performing build pipelines and it really helps to be able to run the pipeline locally and test it out, making sure paths and everything are correct. Couple that with the capability to generate GitHub Actions and other support CI pipelines to run the code is a big benefit.
Adding Security Scans to catch things early is another plus and I am glad that it’s possible to run those scans in multiple ways in Nuke, hopefully the Snyk CLI can be supported in Nuke directly in the future.
If you haven’t checked out Nuke yet, I would definitely give it a try and see the benefits for yourself.