In Part 5, we explored how Dapr bindings let you integrate with external systems like storage and SaaS APIs without pulling cloud‑specific SDKs into your code. At this point, your service can store state, publish events, and interact with external systems, which means it’s time to address one of the hardest parts of distributed systems: observability.
Logs alone aren’t enough once requests cross service boundaries. Tracing is difficult to retrofit. Metrics often depend on vendor‑specific SDKs. And in polyglot systems, consistency becomes almost impossible.
One of the most under‑appreciated aspects of Dapr is that it provides consistent, automatic observability across all building blocks, without requiring instrumentation in your application code.
This post explains what Dapr gives you out of the box, how tracing and metrics work, and why these signals matter long before you reach production.
The Observability Problem in Distributed Systems
In a typical microservice architecture:
- Requests flow through multiple services
- State is stored externally
- Events are published asynchronously
- Failures can occur at many layers
Without good observability, answering simple questions becomes difficult:
- Where did this request fail?
- Was it a timeout or a logic error?
- Which dependency is slow?
- Did the message get retried?
Traditionally, each service and SDK needs to be instrumented manually. Over time, this leads to inconsistent signals and duplicated effort.
What Dapr Does Automatically
Dapr is instrumented internally using OpenTelemetry. This means that as soon as you start using Dapr building blocks, you get:
- Distributed tracing across services
- Metrics for requests, latency, and errors
- Context propagation across service boundaries
- Consistent instrumentation across languages
- Spans for both inbound and outbound calls
Dapr emits:
- OTLP‑compatible traces
- Prometheus‑scrapable metrics
- Structured logs (JSON in Kubernetes)
Crucially, this happens without adding observability code to your application.
Your application emits business logic. Dapr emits infrastructure signals.
Tracing a Request End‑to‑End
Consider a simple workflow:
- An HTTP request hits a service
- State is written using Dapr
- An event is published
- A storage binding is invoked
From Dapr’s perspective, this is a single trace with multiple spans:
- Application request
- State store interaction
- Pub/Sub publish
- Binding invocation
Each span is clearly attributed to either:
- Your application
- The Dapr sidecar
- The external dependency
This separation makes it much easier to understand where time is being spent and where failures occur.
Dapr also records:
- retries
- transient failures
- backoff behaviour
…as part of the trace, something most SDKs require manual instrumentation for.
Note: Dapr uses CloudEvents for pub/sub and input bindings, and automatically propagates trace context across these boundaries.
Viewing Traces in Zipkin (Local Mode)
When running Dapr locally, Zipkin is available automatically at:
As soon as you send a request through your service, Zipkin will show a trace containing:
http://localhost:9411
- the incoming HTTP request
- the state store write
- the pub/sub publish
- the pub/sub delivery
- the storage binding invocation
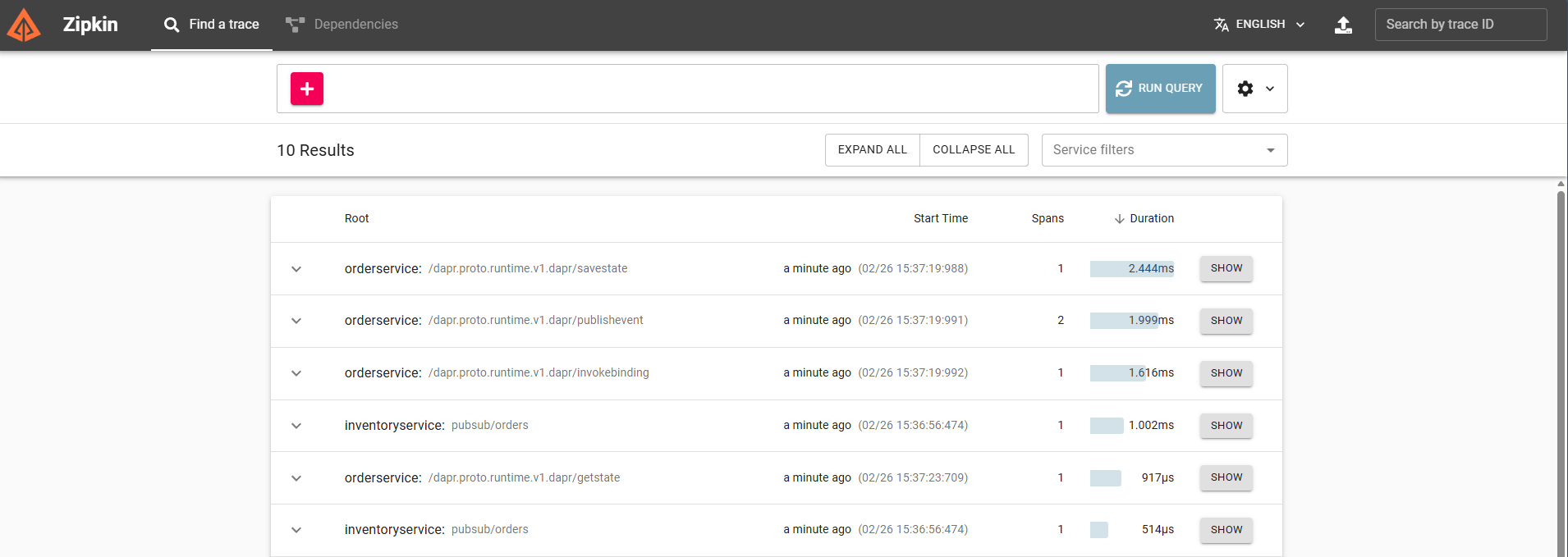
This gives you immediate visibility into latency, retries, and failures, without adding a single line of tracing code.
Using Jaeger v2 with Dapr (Production)
Zipkin works well for local debugging, but some teams choose to use OpenTelemetry collectors and Jaeger v2 in production for deeper analysis, scalable retention, and more flexible sampling. Because Dapr emits OTLP‑compatible traces, Jaeger v2 can be added without modifying your services.
A Jaeger v2 trace for the same workflow typically looks like this:
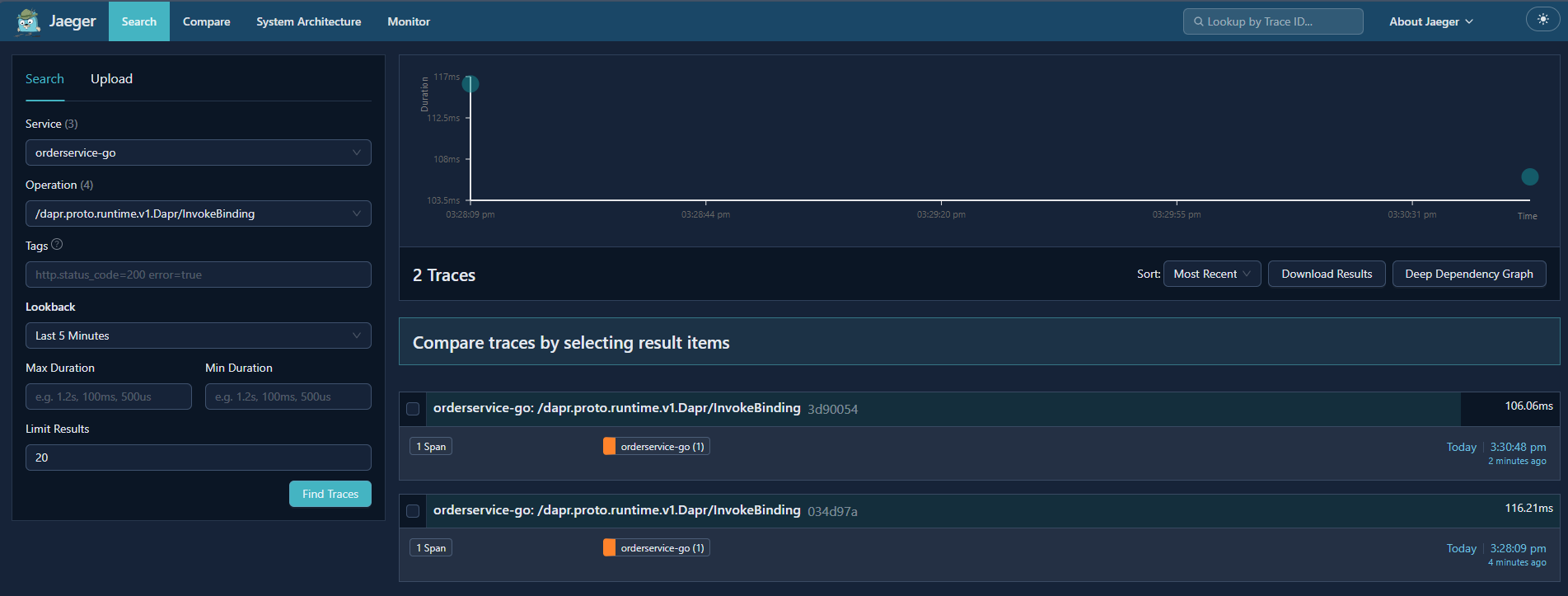
For a deeper look at Jaeger v2 and how it fits into modern OpenTelemetry pipelines, see my OpenTelemetry blog series, which walks through the architecture, configuration, and end‑to‑end workflows in detail.
This gives you a clear path from “local debugging” → “production‑grade observability”.
Observability in Local Development
Observability isn’t just a production concern.
Running Dapr locally gives you immediate insight into:
- Failed state operations
- Pub/Sub delivery issues
- Retry behaviour
- Misconfigured components
Because Dapr runs as a separate process, you can:
- Debug your application normally
- Inspect Dapr logs independently
- See exactly which calls succeeded or failed
- View traces and metrics without adding instrumentation
This makes it much easier to answer:
“Is this a bug in my code, or a configuration issue?”
Note: in local mode, Dapr emits the same observability signals as in Kubernetes, but exporters may differ depending on your configuration.
Metrics That Matter
Dapr emits metrics for:
- Request counts
- Latency
- Error rates
- Component‑level interactions
- Sidecar health and runtime behaviour
These metrics are:
- Consistent across languages
- Independent of application frameworks
- Aligned with Dapr building blocks
- Exported in Prometheus format by default
For platform teams, this provides a common baseline.
For application teams, it removes the need to reinvent instrumentation.
Why This Changes How You Build Systems
With Dapr, observability is no longer something you bolt on later.
Instead:
- Tracing is present from day one
- Metrics are emitted automatically
- Context flows across services without manual wiring
This encourages better system design:
- Clear service boundaries
- Explicit ownership of state
- Event‑driven workflows that are observable by default
It also reduces the cognitive load on developers, who no longer need to think about observability at every integration point.
What Dapr Doesn’t Do for You
Dapr provides signals, not answers.
It does not:
- Design dashboards
- Define alert thresholds
- Replace domain‑specific logging
- Eliminate the need to understand your system
Observability still requires thought and intent, Dapr simply removes much of the boilerplate.
What’s Next
In the final post, we’ll put everything together:
- A service that stores state
- Publishes events
- Writes to external storage
- Emits observability signals
All without infrastructure‑specific code.
This is where Dapr stops being a set of features and starts looking like a platform.
